NIS+ differs from NIS in several ways. It has many new features and the terminology for similar concepts is different. The following table gives an overview of the major differences between NIS and NIS+. The sections that follow the table describe key differences more fully.
| NIS | NIS+ |
|---|---|
| Machine name and user's name can be the same | Machine name and user names must be unique. Furthermore, you cannot have a dot (.) in your machine or user name. |
| Domains are flat--no hierarchy. | Domains are hierarchical--data stored in different levels in the namespace. |
| Names and commands are case sensitive. | Names and commands are not case sensitive. |
| Data is stored in two-column maps. | Data is stored in multicolumn tables. |
| Uses no authentication. | Uses DES authentication. |
| An NIS record has a maximum size of 1024 bytes. This limitation applies to all NIS map files. For example, a list of users in a group can contain a maximum of 1024 characters in single-byte character set file format. | Has no limit. |
| Provides single choice of network information source. | Client chooses information source: NIS, NIS+, DNS, or local /etc files. |
| Updates are delayed for batch propagation. | Incremental updates are propagated immediately. |
NIS+ is designed to replace NIS, not enhance it. NIS was intended to address the administration requirements of smaller client-server computing networks. Typically, NIS works best in environments with no more than a few hundred clients, a few multipurpose servers, only a few remote sites, and trusted users (since lack of security cannot be a crucial concern).
The size and complexity of modern client-server networks require new, autonomous administration practices. NIS+ was designed to meet the requirements of networks that typically range from 100-10,000 multivendor clients supported by 10-100 specialized servers located in sites throughout the world. Such networks are often connected to several unguarded public networks. In addition, the information they store can change rapidly.
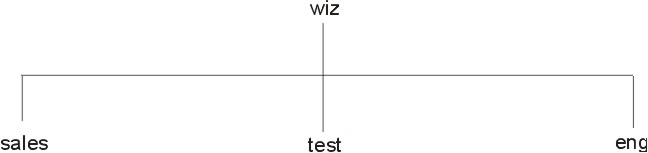
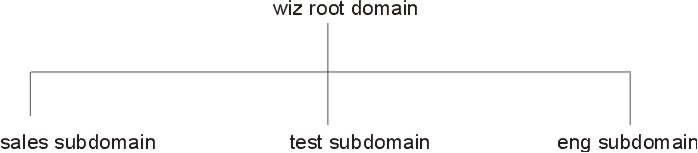
Because more distributed networks require scalability and decentralized administration, the NIS+ namespace was designed with hierarchical domains, like those of DNS. (See figure.) NIS+ domains may be flat, but you can also construct hierarchical NIS+ domains. Such hierarchies consist of a root domain with an infinite number of subdomains as shown in the following diagram.
Hierarchical design makes NIS+ useful for a range of network sizes, from small to very large. It also allows the NIS+ service to adapt to the growth of an organization. For example, if a corporation splits itself into two divisions, its NIS+ namespace can be divided into two domains that can be administered autonomously. Just as the Internet delegates downward the administration of domains, NIS+ domains can be administered more or less independently.
Although NIS+ uses a domain hierarchy similar to that of DNS, an NIS+ domain is much more than a DNS domain. A DNS domain only stores name and address information about its clients. An NIS+ domain, on the other hand, is a collection of information about the workstations, users, and network services in a portion of an organization.
Although this division into domains makes administration more autonomous and growth easier to manage, it does not make information harder to access. Clients have the same access to information in other domains as they would have had under one umbrella domain. A domain can even be administered from within another domain.
The NIS+ domain structure is described in detail in NIS+ Namespace and Structure.
NIS+ provides interoperability features designed for upgrading from NIS and for continuing the interaction with DNS originally provided by the NIS service.
To help convert from NIS, NIS+ provides an NIS-compatibility mode and the nispopulate command. The NIS-compatibility mode enables an NIS+ server running AIX Version 4.3.3 software to answer requests from NIS clients while continuing to answer requests from NIS+ clients. The nispopulate command helps administrators keep NIS maps and NIS+ tables synchronized.
NIS-compatibility mode requires slightly different setup procedures than those used for a standard NIS+ server. Also, NIS-compatibility mode has security implications for tables in the NIS+ namespace.
NIS client machines interact with the NIS+ namespace differently from NIS+ client machines when NIS+ servers are running in NIS-compatibility mode. The differences are:
Note: In the AIX Version 4.3.3 and later releases, the NIS-compatibility mode supports DNS forwarding.
Although an NIS+ domain cannot be connected to the Internet directly, the NIS+ client machines can be connected to the Internet using the /etc/irs.conf and /etc/netsvc.conf configuration files and the NSORDER system environment variable.
The NIS+ client-server arrangement is similar to those of NIS and DNS in that each domain is supported by a set of servers. The main server is called the master server, and the backup servers are called replicas. Both master and replica servers run NIS+ server software and both maintain copies of NIS+ tables.
However, NIS+ uses a different update model from the one used by NIS. At the time NIS was developed, it was assumed that most of the information NIS would store would be static. NIS updates are handled manually, and its maps have to be remade and propagated in full every time any information in the map changes.
NIS+, however, accepts incremental updates to the replicas. Changes must still be made to the master database on the master server, but once made, they are automatically propagated to the replica servers. You do not have to "make" any maps or wait for propagation. Propagation now takes only a matter of minutes.
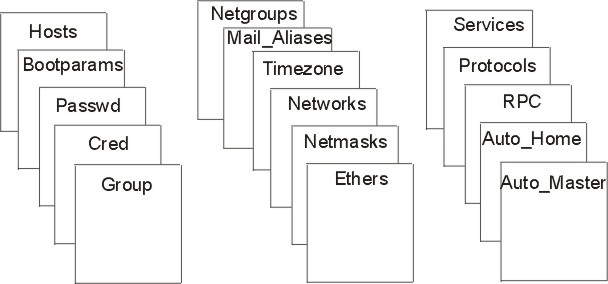
NIS+ stores information in tables instead of maps or zone files. NIS+ provides predefined, or system, tables, as shown in the figure, each of which stores a different type of information. For instance, the hosts table stores information about workstation addresses, while the passwd table stores information about users of the network. The master server stores the original tables, and the replicas store copies.
NIS+ tables are not ASCII files, but are tables in the NIS+ relational database. You can view and edit their contents only by using the NIS+ commands.
An NIS+ table can be searched by any searchable column, not just by the first column (sometimes referred to as the key). This eliminates the need for duplicate maps, such as the hosts.byname and hosts.byaddr maps used by NIS. (To know whether a particular column is searchable, run the niscat -o command on a table. The command returns a list of the table's columns and their attributes, one of which is whether a column is searchable.)
Also, the information in NIS+ tables has access controls at three levels: the table level, the entry (row) level, and the column level. NIS+ tables--and the information stored in them--are described in NIS+ Tables and Information.
NIS maps are located on the server in /var/yp/domainname, whereas NIS+ directories are located in /var/nis/data. The NIS+ tables are contained in the database. The tables' information is loaded into memory as requests are made to the database. Keeping data in memory in the order requested minimizes calls to the disk, thereby improving request-response time.
Another improvement is that NIS+ uses a different updating model from the one used by NIS. At the time NIS was developed, the type of information it stored would change infrequently, NIS was developed with an update model that focused on stability. Its updates are handled manually and, in large organizations, can take more than a day to propagate to all the replicas. Part of the reason for this is the need to remake and propagate an entire map every time any information in the map changes.
NIS+, however, accepts incremental updates. Changes must still be made on the master server, but once made, they are automatically propagated to the replica servers and made available to the entire namespace. You do not have to make any maps or wait for propagation.
The security features of NIS+ protect the information in the namespace and the structure of the namespace itself from unauthorized access. NIS+ security is provided by two means: authentication and authorization. Authentication is the process by which an NIS+ server identifies the NIS+ principal (a client user or client workstation) that sent a particular request. Authorization is the process by which a server identifies the access rights granted to that principal, whether a client machine or client user.
In other words, before users can access anything in the namespace, they must be identified as NIS+ clients and they must have the proper permission to access that information. Furthermore, requests for access to the namespace are only honored if they are made either through NIS+ client library routines or NIS+ administration commands. The NIS+ tables and structures cannot be edited directly.
{kind=link}
{kind=link}
{kind=link}