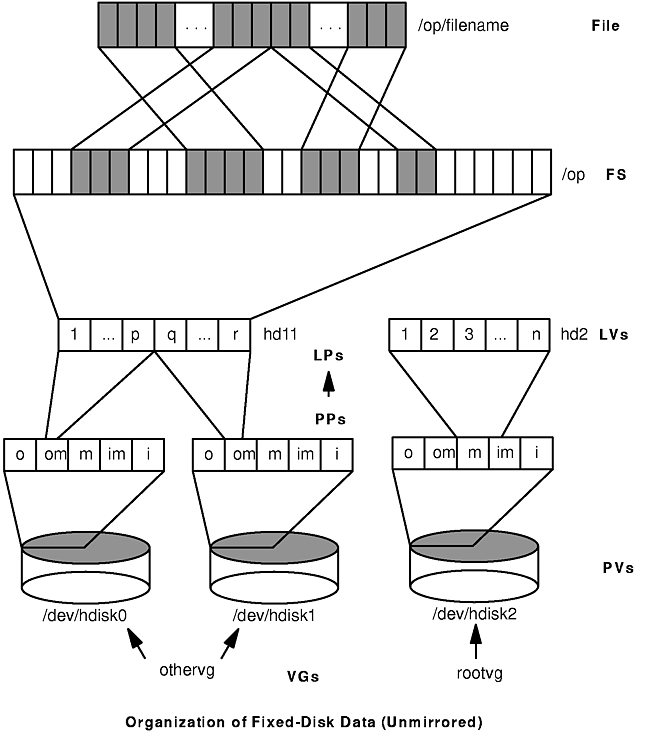
The figure "Organization of Fixed-Disk Data (Unmirrored)" illustrates the hierarchy of structures used by AIX to manage fixed-disk storage. Each individual disk drive, called a physical volume (PV), has a name, such as /dev/hdisk0. If the physical volume is in use, it belongs to a volume group (VG). All of the physical volumes in a volume group are divided into physical partitions or PPs of the same size (by default, 2MB in volume groups that include physical volumes smaller than 300MB; 4MB otherwise). For space-allocation purposes, each physical volume is divided into five regions (outer_edge, outer_middle, center, inner_middle, and inner_edge). The number of physical partitions in each region varies, depending on the total capacity of the disk drive.
Within each volume group, one or more logical volumes (LVs) are defined. Each logical volume consists of one or more logical partitions. Each logical partition corresponds to at least one physical partition. If mirroring is specified for the logical volume, additional physical partitions are allocated to store the additional copies of each logical partition. Although the logical partitions are numbered consecutively, the underlying physical partitions are not necessarily consecutive or contiguous.
Logical volumes can serve a number of system purposes, such as paging, but each logical volume that holds ordinary system or user data or programs contains a single journaled file system (JFS). Each JFS consists of a pool of page-size (4096-byte) blocks. When data is to be written to a file, one or more additional blocks are allocated to that file. These blocks may or may not be contiguous with one another and/or with other blocks previously allocated to the file.
In AIX Version 4, a given file system can be defined as having a fragment size of less than 4096 bytes. Fragment size can be 512, 1024, or 2048 bytes. This allows small files to be stored more efficiently.
For purposes of illustration, the figure "Organization of Fixed-Disk Data (Unmirrored)" shows a bad (but not the worst possible) situation that might arise in a file system that had been in use for a long period without reorganization. The file /op/filename is physically recorded on a large number of blocks that are physically distant from one another. Reading the file sequentially would result in many time-consuming seek operations.
While an AIX file is conceptually a sequential and contiguous string of bytes, the physical reality may be very different. Fragmentation may arise from multiple extensions to logical volumes as well as allocation/release/reallocation activity within a file system. We say a file system is fragmented when its available space consists of large numbers of small chunks of space, making it impossible to write out a new file in contiguous blocks.
Access to files in a highly fragmented file system may result in a large number of seeks and longer I/O response times (seek latency dominates I/O response time). For example, if the file is accessed sequentially, a file placement that consists of many, widely separated chunks requires more seeks than a placement that consists of one or a few large contiguous chunks. If the file is accessed randomly, a placement that is widely dispersed requires longer seeks than a placement in which the file's blocks are close together.
The effect of a file's placement on I/O performance diminishes when the file is buffered in memory. When a file is opened in AIX, it is mapped to a persistent data segment in virtual memory. The segment represents a virtual buffer for the file; the file's blocks map directly to segment pages. The VMM manages the segment pages, reading file blocks into segment pages upon demand (as they are accessed). There are several circumstances that cause the VMM to write a page back to its corresponding block in the file on disk; but, in general, the VMM keeps a page in memory if it has been accessed recently. Thus, frequently accessed pages tend to stay in memory longer, and logical file accesses to the corresponding blocks can be satisfied without physical disk accesses.
At some point, the user or system administrator may choose to reorganize the placement of files within logical volumes and the placement of logical volumes within physical volumes to reduce fragmentation and to more evenly distribute the total I/O load. Monitoring and Tuning Disk I/O contains an extensive discussion of detecting and correcting disk placement and fragmentation problems.
The VMM tries to anticipate the future need for pages of a sequential file by observing the pattern in which a program is accessing the file. When the program accesses two successive pages of the file, the VMM assumes that the program will continue to access the file sequentially, and the VMM schedules additional sequential reads of the file. These reads are overlapped with the program processing, and will make the data available to the program sooner than if the VMM had waited for the program to access the next page before initiating the I/O. The number of pages to be read ahead is determined by two VMM thresholds:
| minpgahead | Number of pages read ahead when the VMM first detects the sequential access pattern. If the program continues to access the file sequentially, the next read ahead will be for 2 times minpgahead, the next for 4 times minpgahead, and so on until the number of pages reaches maxpgahead. |
| maxpgahead | Maximum number of pages the VMM will read ahead in a sequential file. |
If the program deviates from the sequential-access pattern and accesses a page of the file out of order, sequential read ahead is terminated. It will be resumed with minpgahead pages if the VMM detects a resumption of sequential access by the program. The values of minpgahead and maxpgahead can be set with the vmtune command. Tuning Sequential Read Ahead contains a more extensive discussion of read ahead and the groundrules for changing the thresholds.
To increase write performance, limit the number of dirty file pages in memory, reduce system overhead, and minimize disk fragmentation, the file system divides each file into 16KB partitions. The pages of a given partition are not written to disk until the program writes the first byte of the next 16KB partition. At that point, the file system forces the four dirty pages of the first partition to be written to disk. The pages of data remain in memory until their frames are re-used, at which point no additional I/O is required. If a program accesses any of the pages before their frames are re-used, no I/O is required.
If a large number of dirty file pages remain in memory and do not get re-used, the sync daemon writes them to disk, which might result in abnormal disk utilization. To distribute the I/O activity more efficiently across the workload, random write-behind can be turned on to tell the system how many pages to keep in memory before writing them to disk. The random write-behind threshold is on a per file basis. This causes pages to be written to disk before the sync daemon runs; thus, the I/O is spread more evenly throughout the workload.
The size of the write-behind partitions and the random write-behind threshold can be changed with the vmtune command.
Normal AIX files are automatically mapped to segments to provide mapped files. This means that normal file access bypasses traditional kernel buffers and block I/O routines, allowing files to use more memory when the extra memory is available (file caching is not limited to the declared kernel buffer area).
Files can be mapped explicitly with shmat or mmap, but this provides no additional memory space for their caching. Applications that shmat or mmap a file explicitly and access it by address rather than by read and write may avoid some path length of the system-call overhead, but they lose the benefit of the system write-behind feature. When applications do not use the write subroutine, modified pages tend to accumulate in memory and be written randomly when purged by the VMM page-replacement algorithm or the sync daemon. This results in many small writes to the disk that cause inefficiencies in CPU and disk utilization, as well as fragmentation that may slow future reads of the file.
Prior to Version 3.2, users of AIX occasionally encountered long interactive-application response times when another application in the system was doing large writes to disk. Because most writes are asynchronous, FIFO I/O queues of several megabytes could build up, which could take several seconds to complete. The performance of an interactive process is severely impacted if every disk read spends several seconds working its way through the queue. In response to this problem, the VMM has an option called I/O pacing to control writes.
I/O pacing does not change the interface or processing logic of I/O. It simply limits the number of I/Os that can be outstanding against a file. When a process tries to exceed that limit, it is suspended until enough outstanding requests have been processed to reach a lower threshold. Use of Disk-I/O Pacing describes I/O pacing in more detail.
A disk array is a set of disk drives that are managed as a group. Different management algorithms yield different levels of performance and/or data integrity. These management algorithms are identified by different RAID levels. (RAID stands for redundant array of independent disks.) The RAID levels supported in AIX Version 3.2.5 and 4 that are architecturally defined are:
| RAID0 | Data is written on consecutive physical drives, with a fixed number of 512-byte blocks per write. This is analogous to the technique known as striping. It has the same data-integrity characteristics as ordinary independent disk drives. That is, data integrity is entirely dependent on the frequency and validity of backups. This level of function is analogous to the disk striping function described in Logical Volume Striping. |
| RAID1 | Data is striped, as in RAID0, but half of the drives are used to mirror the other drives. RAID1 resolves some of the data integrity and availability concerns with RAID0 if a single drive fails, but becomes equivalent to RAID0 when operating with one or more failed drives. Conscientious backup is still desirable. This level of function is analogous to the logical volume mirroring function of the logical volume manager |
| RAID3 | Data is striped on a byte-by-byte basis across a set of data drives, while a separate parity drive contains a parity byte for each corresponding byte position on the data drives. If any single drive fails, its contents can be inferred from the parity byte and the surviving data bytes. The parity drive becomes the performance bottleneck in this technique, since it must be written on each time a write occurs to any of the other disks. |
| RAID5 | Data is striped block by (512-byte) block, but portions of several (not necessarily all) of the drives are set aside to hold parity information. This spreads the load of writing parity information more evenly. |
RAID devices should be considered primarily a data-integrity and data-availability solution, rather than a performance solution. Large RAID configurations tend to be limited by the fact that each RAID is attached to a single SCSI adapter. If performance is a concern, a given number of disk drives would be better supported by using multiple RAID devices attached to multiple SCSI adapters, rather than a single, maximum-sized RAID.
{kind=link}